Today’s tech talk is about a new feature on The Blue Alliance for this season: predicted match times. It is an open secret among our community that events rarely run on schedule and that published match start times are often meaningless. Until now – TBA now shows a live-updating prediction of when each match will start. This blog post will get into the weeds of how these predictions are generated, a surprisingly tricky problem. This is important to pin down, however, since accurately guessing when a match will start is a key component to the BlueZone (our beta automatic webcast switcher), but more on that later.
Let’s start with some definitions and assumptions. A match cycle is the period between successive match starts: it includes one match, the reset time from the previous match, and team introductions. The cycle time is the amount of wall-clock time elapsed between two successive match starts. Typically, events are scheduled with the assumption of 7-minute cycles. If you look at the distribution of cycle times from a few past events. The distribution of cycle times is centered around 7 minutes, but has a “long tail” of slower cycles. Typically, these slow cycles are due to robots not connecting to the field and requiring FTA intervention, field repairs, or other technical difficulties. These delays are essentially random and very difficult to predict. Thankfully, they’re infrequent, although it takes a long time for the schedule to recover from their effects. Let’s now start by examining the distribution of qualification match cycle times this year.
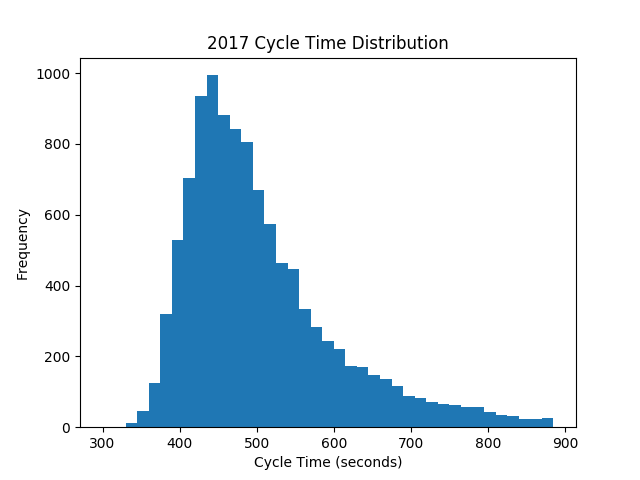
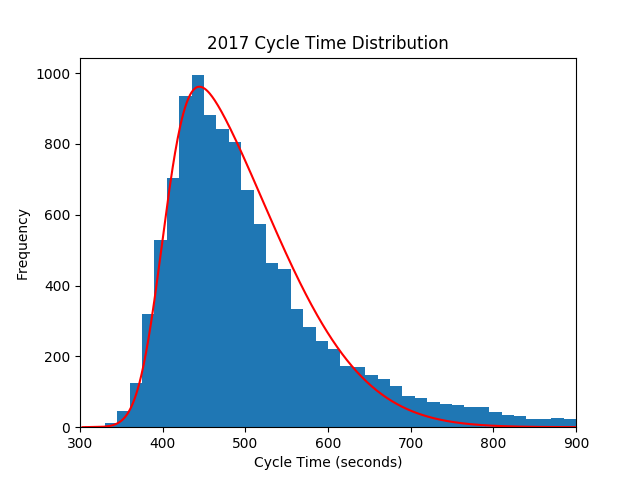
Interestingly, this is pretty close to a skewed Gaussian distribution centered at about µ=400 seconds (slightly less than 7-minute cycles) with a standard deviation σ=120 seconds and a skew parameter γ=4.9. If we draw the (scaled) probability density function over the histogram, it’ll fit nicely.
Next, let’s briefly examine how these outlier cycles affect the overall schedule. It’s very common to get behind due to slow cycles, but it’s much harder to pull off many fast cycles to make that time up.
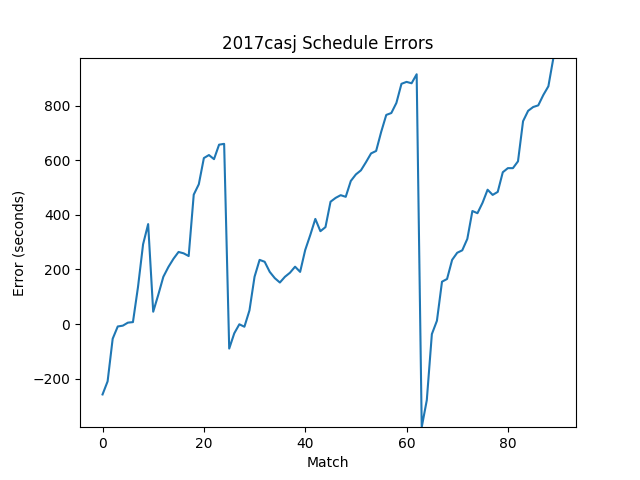
This data shows us the average range of event “on-timeness”. Events can run over two hours behind schedule, but they are rarely more than 15 minutes early. This is due to the fact FTAs want the event to be on schedule, whenever possible. They can adjust the speed of match flow to shift the field earlier or later. Of course, it’s easier to waste time (hello, dance break!) than it is to make it up. We will want our predictions to error on the side of being early. The time prediction algorithm must take this into account and try to “skew” its error in that direction.The first step of predicting match times is to find the ideal cycle time. This is the time it takes to run a match, reset the field, and do team introductions. In other words, this is the cycle time less any random delays. Once we find this time, we can assume that each future cycle will take this long. We find this value by taking into account all cycle times for played matches on the current day. This calculation has a few quirks, however:
- Matches with a scheduled gap of longer than 15 minutes are ignored. We don’t want lunch breaks skewing the calculations. Cycles that take more than 150% of the scheduled time are ignored. In such cases, is likely there were connectivity delays or a field repair before this match which delayed its start. Since we want to under-shoot matches, these outlier cycles are ignored. We assume that “the schedule is king” so cycle times are slightly biased towards the time scheduled.
biased_cycle = 0.7 * real_cycle + 0.3 * scheduled_cycle
We take the 35th percentile of the biased cycle times. Again, we want our computed cycle times to be early and unaffected by long outlier cycles.
One we have the ideal cycle time, we can apply predictions to future unplayed matches. We know the real start time of the most recently played match so we can apply one ideal cycle length in between each subsequent match.
Let’s see how the algorithm performs!
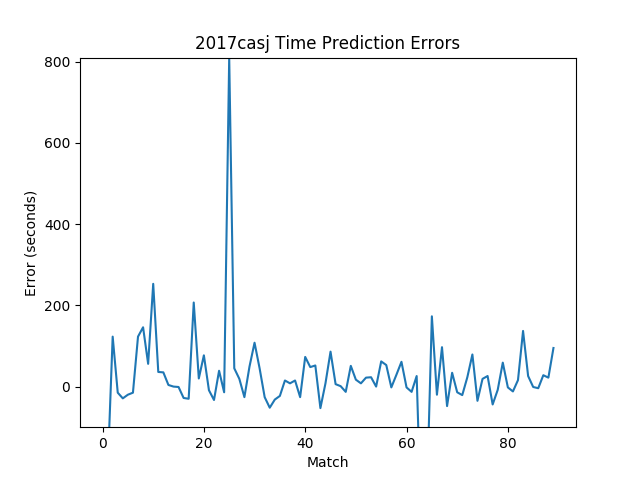
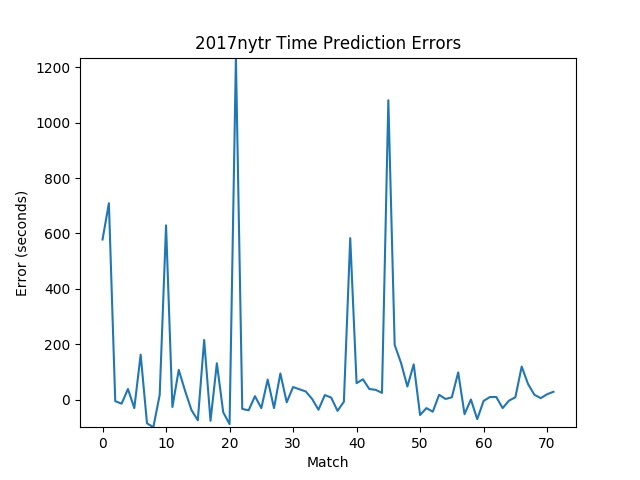
In conclusion, this is a decent attempt at providing more accurate schedule data at events. We can reliably predict a match within 5 minutes of its actual start. Ideally, we still want predictions to be more accurate, otherwise BlueZone will get boring quickly. But this is pushing the limits of what we can do, given the known variability of cycle times. Furthermore, our predictions have to be a little extra lenient because we don’t know exactly when a match starts (instead, we only know when matches end). This means it’s difficult to tell if a 2-minute delay is due to the match not having started yet or if the match is already over but scores haven’t been posted yet.
Next year, we’re looking at using Computer Vision technology (similar to what powered @FRC_Replay during champs) to determine when matches actually start by inspecting the Audience Display overlay on the webcast. We aim to always be improving our offerings to make it easier for you to follow your favorite teams.
Like this kind of thing? All the code for this blog post is on my GitHub. In addition, The Blue Alliance is an open source community driven project and we’re always looking for new contributors. Drop us a line if you’d like to get involved!

Very interesting stuff!!! Appreciate the blog!
I wonder if you can record the exact start/end times of matches by having the computers at each field save match information the moment key events happen? Every match has a start (“toes behind the line… 3… 2… 1… go!) followed by autonomous time then tele-op time and those times are known the instant they happen. No need for vision tech, right?
FMS will publish the exact timestamp a match starts, that’s already used in this algorithm. The issue is that the data doesn’t get posted until after the match is completed and the final scores are committed by the Scorekeeper. We can compute the exact timings like you described for matches in the past, but not for the current/future ones. That’s where this algorithm comes into play. If we want to know exactly when a match starts, we’ll have to use something more real-time that what we have already. Webcasts have the score overlay in a known format, so it’s pretty straightforward to apply OpenCV to the stream and determine when matches have started.
Your best bet for using vision tech may be to do something like counting the number of people on the field, or looking for the green light in the webcast. I just watched a couple, but it seems like it’s visible. The match can’t start if the light isn’t right. Depending on the view, you may be able to see the lights above each driver station.
[…] Predicted match times, so you know when a match will actually start, based on the event’s current timeliness. For more information on how these work, see this tech talk blog post. […]