Preface: This article may make mildly more sense if you have the mathematical background of OPR, which you can get in a post by Eugene Fang here.
In the world of FIRST Robotics strategy, the term Offensive Power Rating (OPR) seems to continue to hold ground every year. How could it not — it’s an easy metric to find, being in FRC Spyder, the TBA app, and on The Blue Alliance itself. However, how good OPR is as a metric for team strength varies year to year and is heavily influenced by game design.
Linear and non-linear scoring
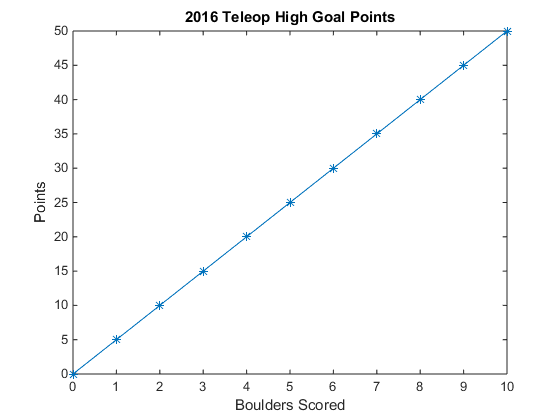
Scoring can fall under two major categories: linear, and non-linear scoring. Linear scoring means that achieving a certain game objective yields the same number of points, regardless of how many times it is achieved. A recent example of linear scoring is would be scoring boulders in the high or low goals in the 2016 game, FIRST Stronghold. Within a given mode (autonomous or teleop), scoring a boulder is always worth the same number of points. When plotted, this looks like a straight line (linear scoring).
A recent example of nonlinear scoring would be rotors in the 2017 game, FIRST Steamworks. A different number of gears is required to spin up each rotor, in addition to the “free gear” in the airship at the beginning of the match. When plotted, this is NOT a straight line (non-linear scoring).
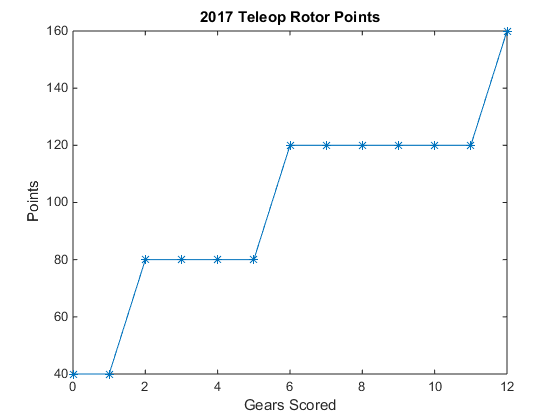
This isn’t even taking into account the different autonomous and playoff rotor bonuses, which made scoring even more non-linear.
Linear and non-linear team contribution
Even if scoring is linear, team contribution can still be linear or non-linear. Linear team contribution means that one team’s actions (and points earned from the action) do not affect the actions (and points earned) of another team on the same alliance. In other words, linear team contribution means that an alliance’s score would be exactly equal to the sum of each team’s individual score if they were to play the match alone. This can be a subtle concept to grasp, so here are some examples.
Example 1 (linear): Climbing the rope in FIRST Steamworks (2017) because there was one rope for each team, and teams didn’t affect each other’s ability to climb (outside of extreme circumstances).
Example 2 (linear): Scoring fuel in FIRST Steamworks (2017) under the assumptions: 1) teams don’t get in the way of each other when scoring and 2) teams don’t starve alliance members of fuel.
Example 3 (non-linear): Capturing the tower in FIRST Stronghold (2016) was an all-or-nothing scenario; all three teams had to be in position to earn points — if one team failed, then no points were earned.
Example 4 (non-linear): The entire game of FIRST Overdrive (2008). Because there were only two game pieces for three robots, having three elite robots wouldn’t yield significantly more points than just having two.
Example 5 (non-linear): Recycle Rush (2015) at the highest levels of play. Since there was limited space to maneuver on the field, a third robot would often only get in the way of the other two instead of contributing in a meaningful way.
How non-linearity scoring and team contribution affect OPR
OPR’s mathematical model assumes linearity in scoring and team contribution. While things are rarely perfectly linear, a linear model is often good enough and greatly simplifies the math. The more the actual game deviates from the linear model, the less accurate OPR usually is. This distinction between linear and non-linear is not only useful for judging the accuracy of OPR but also in being aware of strategic match play.
Other factors
While linearity is a major component of how well OPR estimates team strength, there are also many other factors that may have just as much impact. Aspects of a game that are random significantly hinder how well OPR can work. Randomness can come from a task that causes many teams to be inconsistent (e.g. climbing in FIRST Steamworks) or penalties, be it those too easy to incur or yellow & red cards.
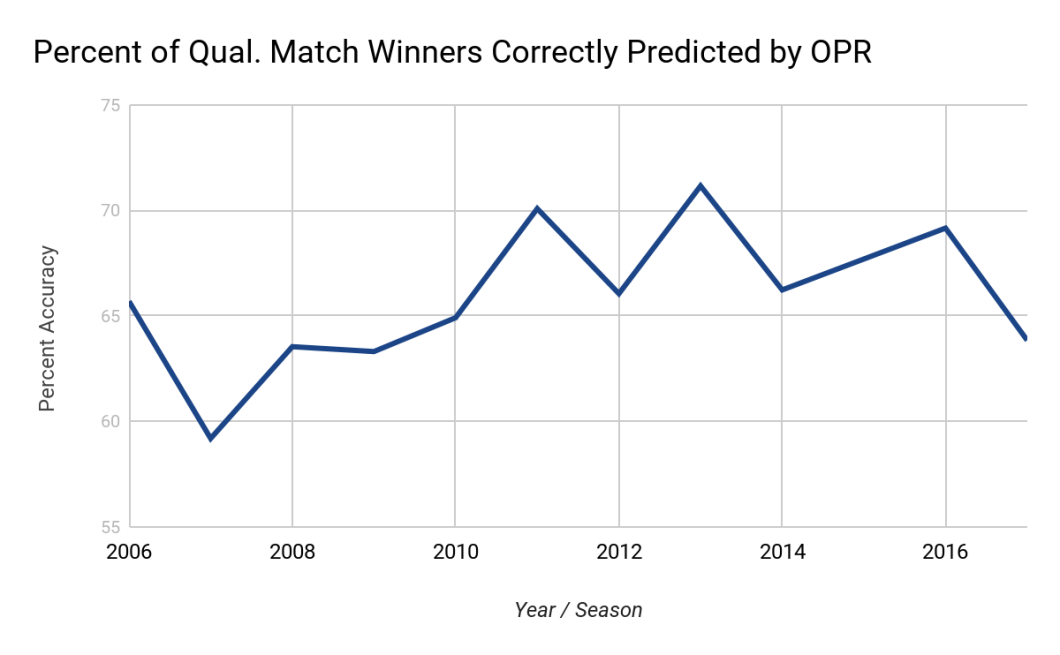
Here is a graph showing the percentage of qualification match winners correctly predicted by OPR over the years. What do you think contributed to the effectiveness (or ineffectiveness) of OPR for each year?
Conclusion
Given that OPR only needs the final alliance score, the lowest common denominator in determining a winner, it can be applied to (almost) any year of FRC, from the beginning to the future. Its simplicity and overall reliability (some years more than others), makes it a versatile tool for many teams and continues to be used to this day. However, it also important to understand that because of its limitations, OPR can always supplement, but never replace, proper scouting.
Note: Thanks go to Eugene Fang, Brian Maher, Justin Tervay and countless others for being so receptive and helpful as I ranted out the prototype version of this.
