On March 16th, 2019 (Pacific Time), The Blue Alliance went down for 3 hours from ~21:00 to 23:59 due to a combination of overrunning a daily budget cap set on the tbatv-prod-hrd Google App Engine project, and an error in the Google Cloud Console that prevent increasing the budget. This prevented usage of the website, API, and signed-in usage of the iOS app.
This document is a postmortem diagnosis of what went wrong, and what steps are being taken to prevent similar issues in the future. We are sharing it publicly so others can see a postmortem process, and better understand how TBA operates.
https://github.com/the-blue-alliance/the-blue-alliance/issues/2464 is the parent issue to track follow ups from this incident.
This is also shared on ChiefDelphi at https://www.chiefdelphi.com/t/postmortem-tba-16-march-2019-site-outage/350793
Impact
For around 3 hours, users were unable to use The Blue Alliance website or API. The Blue Alliance for iOS app crashed on launch for users signed into the MyTBA feature, resulting in ~1500 crashes for ~300 users during the outage.
Fortunately, we overran quota late in the evening, limiting user impact.
Timeline (all times Pacific Time)
- Mar 16th, 9:21pm – First 500 error due to quota overrun
- 9:30pm – Google Cloud Monitoring sends an alert to #monitor on Slack about 500s spiking
- 9:32pm – 500s peak at 46 qps (queries per second).
- 9:34pm – Eugene becomes aware of quota overrun, asks Greg on Slack and Facebook Messenger to increase GAE quota with instructions how to do so.
- 9:37pm – Greg attempts to increase quota, but gets error in Google Cloud Console when accessing GAE settings. Greg only has his phone with him, so debugging is challenging.
- 9:49pm – Greg creates #site-down on Slack to coordinate response.
- 9:53pm – Zach shares that iOS app is crashing on launch due to failure to receive an expected response from server.
- 10:26pm – Greg determines no further action is possible, and goes to sleep.
- Mar 17th, 12:00am – Quota resets every 24h. After reset, site comes back up.
- Later that morning – Greg increases daily quota from $20 to $100. Incident fully resolved.
Figures
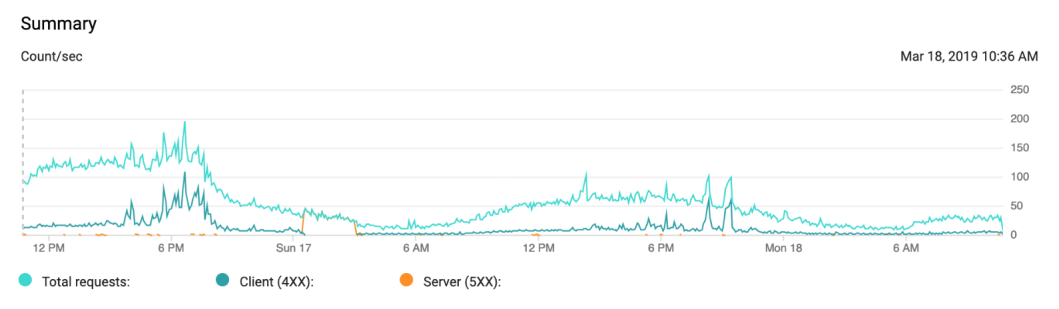
Google App Engine response time series (shown in Eastern Time). Observe all responses become 500 errors for 3 hours in the early morning of Sunday, September 17th.

Over Quota Error. This is what visitors to The Blue Alliance site saw during the outage. The 3rd party and mobile app APIs were also down. Some pages would continue to serve if users hit CloudFlare caches instead of reaching the Google App Engine server.
Google Cloud Console App Engine Settings Error Screen. This error message presented itself when Greg attempted to increase the quota, with different tracking numbers over time. The errors stopped displaying after our quota reset.
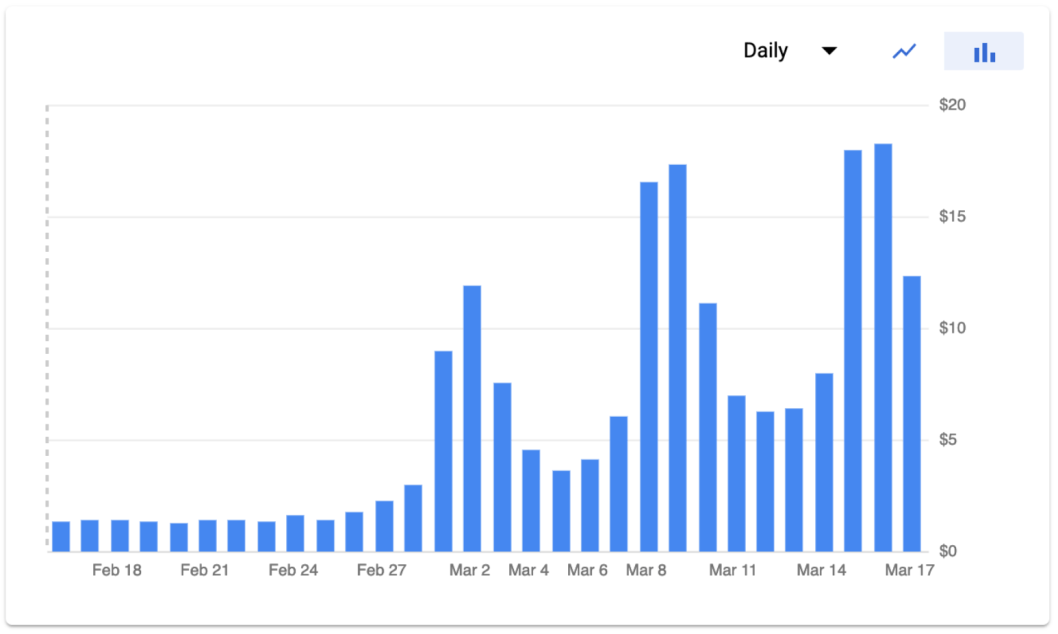

Daily Google App Engine costs. Google estimates cost to implement quota limits, so March 16th did not fully reach $20.
Detection
How did you know something was broken? Did you have alerting to find it for you, or did you need to rely on humans catching/reporting?
- 9:30pm – Google Cloud Monitor bot sent a message to #monitor about a spike in #500 errors However, its message does not generate push notifications to site admins.
- 9:34pm – Eugene noticed that the site was erroring while attempting to use it for scouting purposes.
No proactive “approaching quota” alerts fired. No alerting sent push notifications to site admins.
Escalation
How hard was it to get the right people in the room to fix the problem?
Eugene messaged Greg on Slack and Facebook Messenger. Greg had Slack Notifications on his phone off, and did not have his laptop with him. It was a fluke Greg was awake, given the late hour.
Remediation
What did you do to fix the issue? How hard was it? What could we do better?
Greg attempted to increase the GAE daily quota, but was stopped by the erroring settings page.
We waited 3 hours until midnight pacific time, when our Google App Engine quota reset. This restored the site. The GAE settings no longer errored, and Greg increased the daily quota.
Eugene should have had permissions to fix this problem himself.
Prevention
What tooling/code/process improvements should we make to have prevented this in the first place?
We need proactive alerting for quotas. Alerts need to notify site admins with push notifications. All admins need appropriate permissions.
Poor Detection
We were surprised that the site went down, and it was detected by an admin experiencing an error, not by proactive alerting.
Recommended Follow-ups:
- Alerting – We should connect a Google Cloud PubSub topic to quota alerts, and have it automatically post in Slack. This will allow us to proactively catch quota issues, instead of discovering them from user reports. Tracked in https://github.com/the-blue-alliance/the-blue-alliance/issues/2466
- Notifications – The Google Cloud Monitor bot in Slack should alert the channel. It doesn’t seem to have this functionality, so we may need to hack something else.
Google App Engine Daily Quota Exceeded
The Blue Alliance exceeded $20 of Google App Engine predicted quota in a single day for the first time on Saturday, March 16th, 2019. March 16th had $18.28 billed, while the previous Saturday was billed at $17.31. The Blue Alliance incurs Google Cloud Platform costs other than Google App Engine, but the App Engine budget quota is what took the site offline.
Recommended Follow-ups:
- DONE Increase Quota – We have increased the daily quota to $100.
Admins Did Not Have Permissions
Eugene discovered the issue, but only Greg and Phil (who were in Eastern Time, where it was after midnight) had permissions to increase GAE quota. It was a fluke Greg was awake and available, as he was away from home for the weekend.
Recommended Follow-ups:
- DONE Give Eugene permissions – Eugene administers the TBA services, so should have permission to change budgets. Eugene has been given these permissions.
Google App Engine Settings Errors
We were unable to increase the quota once we had overrun it. We believe there is a bug in the Google Cloud App Engine Settings console that prevents accessing settings once quota is overrun, which prevents increasing quota. After our quota reset, we were able to increase the quota.
Recommended Follow-ups:
- Understand Bug – We do not know whether others have encountered this issue before. Tracked in https://github.com/the-blue-alliance/the-blue-alliance/issues/2467
- DONE Bug Reporting (via GAE) – We used the GAE bug reporting tool to report this issue.
- Bug Reporting (to a human) – We should tell a person we know who works on Google Cloud about this.
No Google Technical Escalation
We have no human contact at Google to escalate technical issues to. In the event our GAE settings continued to error, we would have no remediation path to fix the problem. This could present a problem for similar issues in the future that might require intervention by a Google employee to fix.
Recommended Follow-ups:
- Find an FRC alum who works on Google Cloud – We should find someone inside of Google to whom we can escalate future issues that we are unable to self-remediate.
iOS App Crashing Due To Expected Response
The TBA mobile apps cache data locally, so should continue to work even if the server is down. However, the iOS app attempts to sync push notification tokens for signed in users with the MyTBA endpoints on app launch. The iOS app was expecting a valid responses from the MyTBA endpoints, which resulted in users crashing on launch.
Recommended Follow-ups:
- DONE Don’t Crash – Responses from the MyTBA endpoints should fail gracefully. Fixed in https://github.com/the-blue-alliance/the-blue-alliance-ios/pull/515 and deployed in v1.0.8.
- Audit App Launch – Code paths involved during app launch are critical, and should fail gracefully.
