Background
For the past 4 years, FRC has followed the general ranking structure of 4 possible ranking points (RPs) per match, 2 for winning and 2 for bonus objectives. 4 years is long enough for me to consider this a trend and not just a fad of FRC game design, so I thought I would take a look at improving my bonus Ranking Point predictions. Better RP predictions will really improve my ranking projections and future analyses I do that rely on them. The current method I use to predict bonus RPs in my simulator has some notable downsides that I’ll describe here, and I’ll also go into how I’ve improved on them with my new methodology.
Old methodology (Predicted Contributions)
To set the stage, my old method for predicting RPs was to have 3 ratings for each team, one for their Win/Loss/Tie strength, and one each for the bonus RPs. The WLT Strength would come from Elo and OPR, and the bonus RP strengths would come from calculated contributions to each RP completion. I’ll be focusing just on the bonus RPs in this post. For an upcoming match and for each bonus RP, I would add that RP’s ratings of the three teams together to get the probability that they would achieve the given RP in the match. I would cap these probabilities at 0% and 100% if the sum of the ratings exceeded those bounds. This was a simple and easily implementable method with reasonable theoretical foundation, but we can do better. The main problems I had with this method were:
- The existence of 0% and 100% predictions.
- Ratings could change in the wrong direction after a match
- Overall predictive power wasn’t as high as I wanted it to be/could be
Let me go over each of these problems in more detail, and along the way I’ll explain my alternative, which I am dubbing Iterative Logistic Strength (ILS):
The Existence of 0% and 100% Predictions
When working with probabilities, you should never make 0% or 100% predictions unless the alternative is literally impossible. For example, if you’ve got a pretty weak alliance in 2019, it’s pretty unlikely that your team will score over 150 points, but you shouldn’t say 0%, as there’s always a chance that, for example, the other alliance racks up 100 penalty points for you. What we can say though is that there is a 0% chance that your team scores 10.3 points, as this is an unachievable score. If you make a graph of an alliance’s RP strength versus their calculated probability under my old system, it will look something like this:
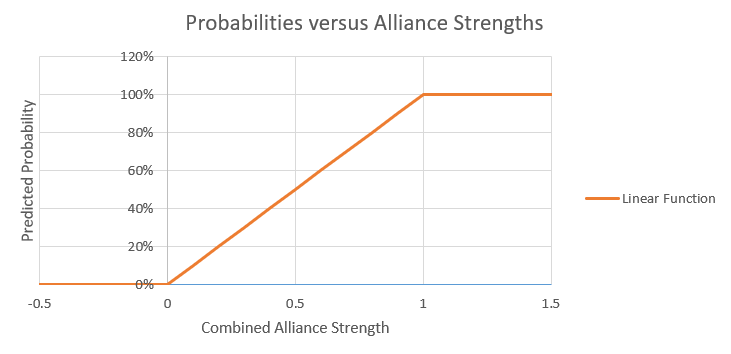
There’s not really any problem when the alliance strength is between 0 and 1, but since strengths below 0 and greater than 1 are possible, we run into some trouble because of the caps. You could always choose to use different caps, like 5% and 95% for example. But those would be arbitrary and would mean that even if you had the best alliance possible that should get the RP 999 times out of 1000, you could never exceed 95%. What we would like instead is a conversion function that asymptotically approaches 0% for large negative team strengths and 100% for large positive team strengths, without changing the intermediate probabilities too much. The function I’m going to use for this is the logistic function, which is the same function I use in Elo ratings. Graphing the logistic function alongside the capped linear function shows the difference.
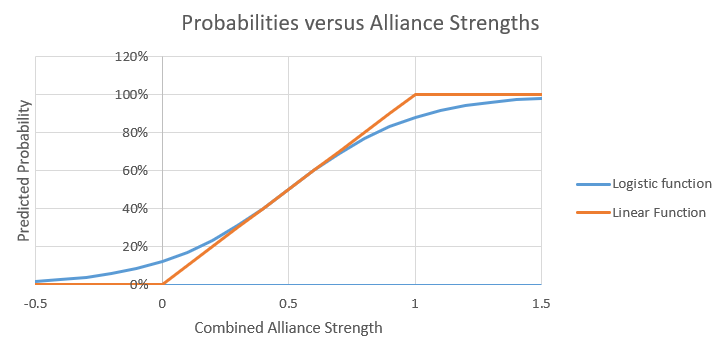
That looks a lot better, and has all of the properties we want.
Direction of Rating Changes
One really big issue I had with the old system was that individual team ratings for their RP strength could drop even if they got the associated RP in a match, or increase even if they did not. This has to do with how predicted contributions work, but at the root, if an alliance’s combined rating exceeded 1 and then they achieved the RP, they would still be “underperforming” their expectations and one or more teams on that alliance would see their ratings drop as a result. For example, here are 33’s HAB RP Strengths over time at IRI:
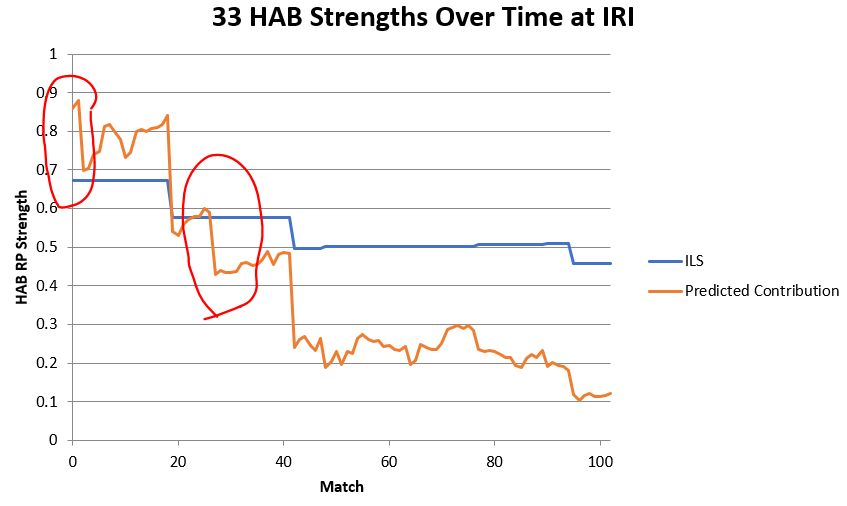
Notice the huge drops in the PC Rating at matches 2 and 27. In both of these matches, 33 did indeed achieve the RP, but their PC Rating still drops noticeably. Their ILS Rating in contrast raises incredibly slightly after these matches, to the point that the change isn’t even visible on the graph.
If we know going into a match that a team’s rating will drop no matter what they do, that’s a poor rating, and we should just start them lower. To combat this, my new system will iteratively estimate a team’s strength based on the results of each match. In case you were wondering where the name comes from, it comes from the fact that we’re using an iterative method on a logistic function to calculate team strengths. This iterative nature is in contrast to predicted contributions, which at any time are a kind of average of a team’s max previous calculated contribution and their current event calculated contribution.
So essentially, before each match, we combine team strengths to get an alliance strength, and feed that into the logistic formula above to get an RP success probability. After the match, we compare our prediction to the result. Just like Elo, if the prediction is close to the result, team ratings only change a little bit, and if the prediction is very different from the result, team ratings change a lot. I have found experimentally that the optimal amount to change is 0.1 * (actual result – predicted result), which means that a team’s rating will change by at most 0.1 in one match. For example, say we predict an alliance has a 30% chance of getting an RP. If they get the RP, all teams on that alliance will have their ratings increase by 0.1 * (1 – 0.3) = 0.07, and if they do not achieve the RP, their ratings will change by -0.03. This is how we avoid the over-rating problems that predicted contributions run into. Teams will always have the capacity to improve their rating by achieving RPs, and will always have the possibility of lowering their rating if they do not.
Overall Predictive Power
This is really the big one, it doesn’t matter if a prediction methodology has good theoretical foundations or has a cooler name if you’re losing predictive power. Fortunately, most systems with poor fundamentals will also have poor predictive power. To directly compare ILSs against calculated contributions, I made predictions for all 2019 championship matches using both methodologies. Here is the top-level summary of Predicted Contribution (PC) and ILS predictive powers using both log-loss scoring and Brier scores (lower is better in both):

The predicted contributions have a log-loss score of +infinity for both RPs. This is because in at least one case for both, a probability of 100% was predicted when the RP ended up not being earned. Log-loss systems give an infinite penalty for this mistake, so ILS just wins on that score by default since this system never made that mistake. Looking at the Brier scores though, we still see some solid improvement when using ILSs over predicted contributions.
Start of Season Ratings
This probably isn’t super important to most, but for the curious here are how I seed the ILSs and PCs at the start of the season. For predicted contributions, I seed all teams at 90% of their previous season’s normalized max OPR, which is then normalized onto the week 1 calculated contributions for that category. For ILS, I find the rating that when multiplied by 3 would give the week 1 average RP rate. Then, for each team, I adjust this rating up or down based on their start of season Elo. The optimal value I found for this adjustment was to use 0.001*(start of season Elo-1500). Basically, this means a 100 point Elo change will increase your start of season ILS by 0.1. This provides noticeable predictive improvement over just starting all teams at the same rating.
Results
I have attached here the end of season ILSs for each RP in 2016 through 2019. Here are the top rated teams for each RP:

I have also added them into v10.1 of my event simulator for use in offseason comps (it would be a lot of work to backfill in-season events so I’m not going to bother) . If we get bonus RPs next year this will be my standard approach there as well. I did attempt to take a weighted average of the two systems like I do for match prediction with Elo and OPR, but there is no predictive improvement when doing this when compared to just using ILS.
Just to show one of the first things that catalyzed me to change my system, here is 2052’s chances of getting >=17 RPs at the Minnesota State Champs:
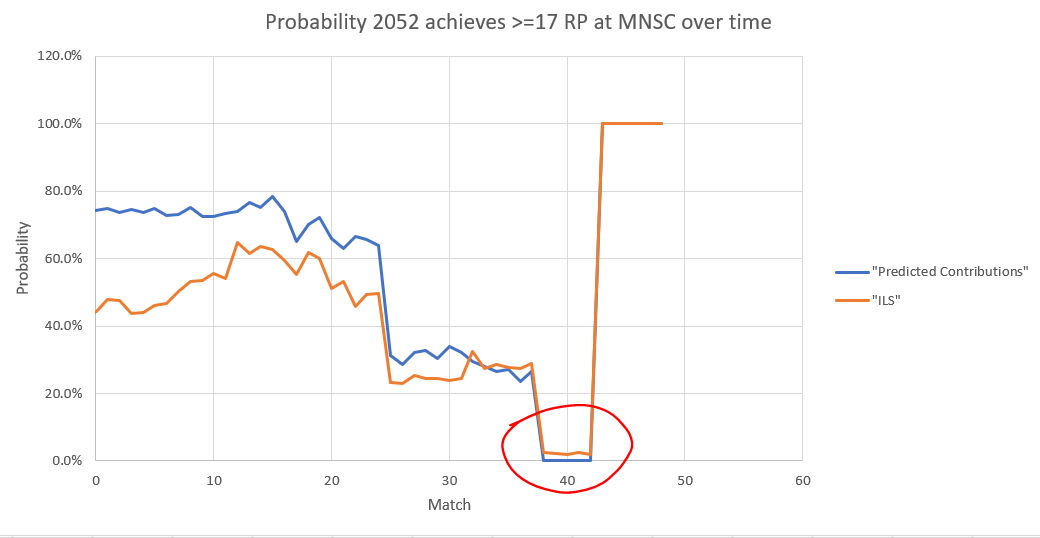
Look at the set of matches around match 40, between 2052’s second to last and last match. Predicted contributions give them a 0% chance of achieving the rocket RP in their final match, which means they can achieve at most 16RPs as they have 13RPs going into that match. ILS on the other hand gives them about a 2% chance of getting all 4 RPs, and that is indeed what happened.
I’m pretty happy with how these turned out. I got annoyed every time I saw my simulator predicting an RP at 100%, so maybe this will make me a happier person. 🙂 Now I just have to hope we actually get bonus RPs next year so my effort isn’t wasted.
-Caleb
