Introduction
Hello everyone, I’m happy to make my inaugural post on TBA Blog. Recently, I’ve noticed that much of my work in my Miscellaneous Statistics Projects thread has essentially become a blog. What I mean by that is that I spend a lot of time writing and editing these posts and was in a sense breaking the “forum” style of CD since I make well over half the posts in those threads. I also wanted more formatting tools at my disposal, so I decided to write in a blog. The plan for now is for me to use this platform for some of my thoughts which would otherwise go on CD. I appreciate feedback, so if you have any thoughts or suggestions on what I can improve in this format, please let me know. Without further ado, let’s get into it.
Background
A few weeks ago, I hosted the Chezy Champs Ranking Projection Contest. I’ve done match prediction contests before, but with my new ability to project ranks before events start, I thought it might be fun to see how my ranking projections stack up to others’. Ian H won that contest, but Ari was kind enough to share a full probability distribution for each team to achieve each rank, so I wanted to compare my ranking distributions against Ari’s to hopefully identify weaknesses in my event simulator. I’ve uploaded a book titled “CC Ranking Comparison” to CD which does this. In addition to Ari’s predictions and my predictions, I’ve added a baseline set of predictions under the name “Ignoramus”. These predictions simply predict that every team has a 1/42 chance of achieving every rank.
Detour on Error Functions
For each of these distributions, I found the squared error and the log loss error for every prediction. You all may be familiar with squared errors from my previous work, but I think I am going to be transitioning to log-loss for much of my work going forward. Essentially, the log loss error is just -LOG(1-ABS(predicted probability – actual result)). Here’s a graph that shows the difference between the two error functions (note that I scaled down the log function by a factor of 3 to make the graph more readable):
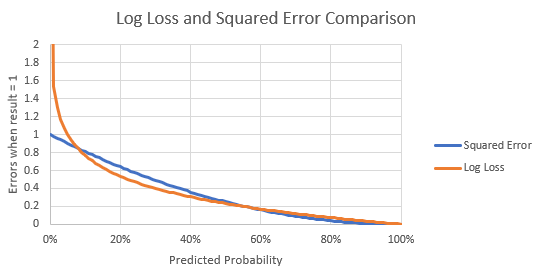
As you can see, the graphs are reasonably similar for predictions everywhere except the very poor predictions. You can’t see it because I truncated the y-axis, but the log-loss graph actually goes all the way up to +infinity, meaning that if you ever predict something as 0% and then it occurs, you made an infinitely bad prediction under the log-loss formula. There are lots of choices for error functions, and both of the above choices are reasonable. However, from what I’ve seen, log loss is generally agreed to be a superior error function out in the real world due to it better approximating the step function between 0 and 1.
Results
Anyway, I calculated errors with both methods for all three ranking distributions. Here are the top-level results for all predictions (lower is better):
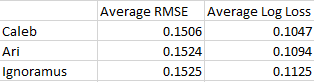
We can see that my predictions came out on top in both methods, Ari got second, and Ignoramus got last. Which is a good sign! That means both Ari and I have more predictive power than the blind assumption that all teams are exactly equal. The amount by which my predictions beat Ari’s depends on the formula you use. In the RMSE formula, mine appear drastically better than Ari’s when referenced against Ignoramus, but in the log loss method, my predictions are only about twice as good as Ari’s compared to Ignoramus’. Don’t mind the magnitude difference between the RMSE and log-loss methods, it doesn’t make sense to directly compare different scoring methods in this way.
At a team level, here were the teams where I made worse predictions than Ignoramus according to the log-loss function:
- 696
- 1538
- 8
- 5818
- 604
- 3476
- 4488
- 1072
- 5012
- 3309
And here were the teams where I made worse predictions than Ari according to the log-loss function:
- 696
- 3310
- 8
- 4488
- 5012
- 5818
- 3476
- 3309
- 3647
- 604
- 5924
- 2990
- 4388
- 2910
- 846
I’ll be doing my own private investigation into all of these teams to see if there are any noticeable similarities, but if anyone thinks they see an obvious pattern among them I’d love to hear it.
Thanks
Huge thanks to Ari for putting out his predictions, I’m very happy someone else made something that I could compare myself against, as without that I’m blind to how good or bad my predictions actually are. I’m excited to see what else he puts out in the future.
Until next time,
Caleb

[…] leveraging The Blue Alliance’s expansive data (you know how we love data), we’ve created the data-rich features like match breakdowns, event stats, and detailed team […]