There’s a ton of data on The Blue Alliance. We have data about individual matches, OPR for an event, insights over years, tons of match videos, and so much more. But, how do we use that data effectively?
There’s a lot to be said about casually browsing the site and taking in the information as a human. But, that’s just one way we can use the data. What if we used a bit of machine learning? Ideally, a machine learning model would allow us to do a few things:
- Effectively summarize our data
- Predict things about our data
- Provide us with insights (ideally ones we wouldn’t have found on our own)
A brief overview of Machine Learning
As I was surfing the documentation for scikit-learn recently, I saw this image that might be helpful as we begin our discussion:
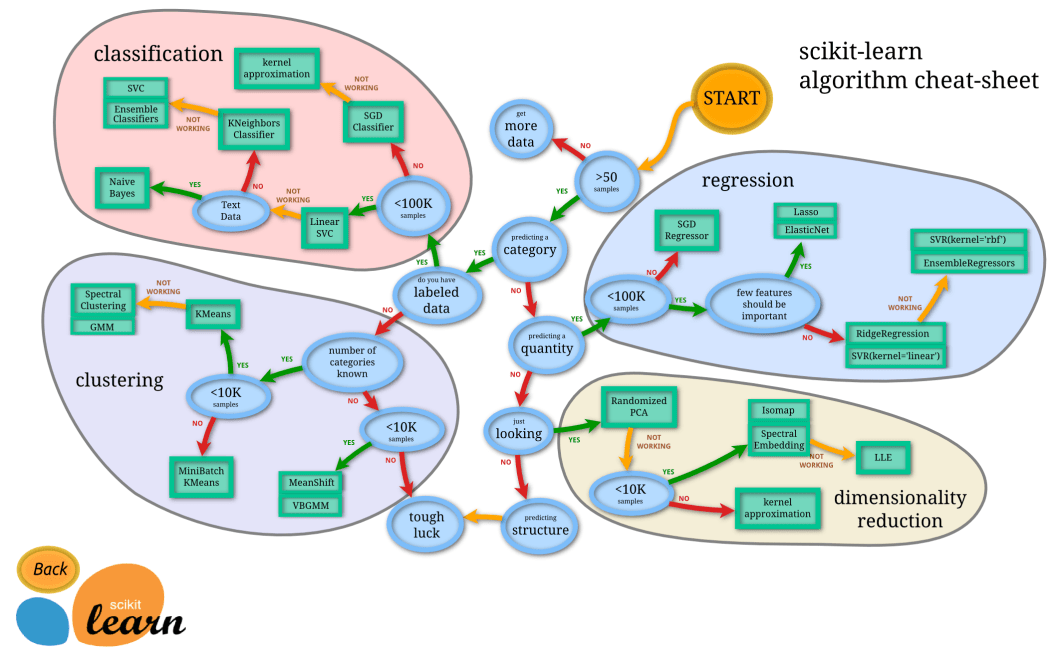
Most of the press these days is given to a very specialized machine learning technique called Deep Learning, which relies on multiple layers of neurons. It’s not part of the library of algorithms provided by scikit-learn, but it would best fall under the SGD Classifier and SGD Regressor parts of the graph – the exact one depends on how you set up your network’s loss function.
However, there’s a lot of other machine learning algorithms. Most of the folks in FRC are probably familiar with a technique called linear regression; it’s typically covered in a high school math course.
Logistic Regression
In this blog post, I’m going to dive into a bit about logistic regression and build some theory that will help us build a model to predict the likelihood teams will win awards. This is one of the more common variations of a linear regression.
For those who would like a quick refresher, linear regression looks something like this: we hand our linear regressor some data, with some independent variables and dependent variables. With some math, the regressor then tries to fit a line by tweaking coefficients to the independent variables and calculating an intercept. We define the best line to be the one that reduces the squares of the error of the model’s predictions (this is called least squares), and we just iterate for a bit. It turns out that this has an analytic solution that’s briefly touched on in our blog post about calculating OPR. (Yep, you read that right. OPR is just a linear regression.)
Instead of fitting a line, logistic regression fits a logistic curve, which has a characteristic S-shape:
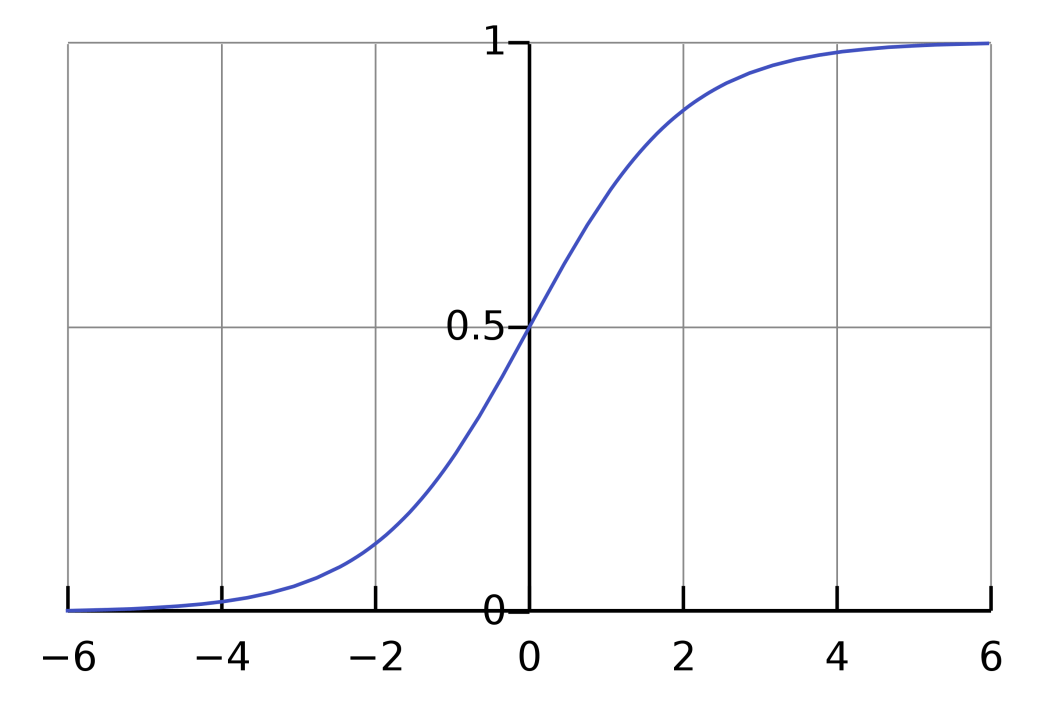
To fit this curve to our data, we just take the logarithm (typically the natural logarithm, though any base will do) of each of our variables – both independent and dependent. It turns out that fitting a regular line to this data becomes a logistic curve when we undo the transformation. We just do linear regression as per normal from here.
There’s a few benefits our logistic regression model has over more fancy machine learning techniques:
- Doesn’t need as much data. This is important, because we actually don’t have a ton of data in FRC. State of the art neural networks consume hundreds of thousands of training data instances. (Think like the scale of Wikipedia.)
- Tends not to overfit as much as other algorithms. Logistic regression is not a terribly powerful model. We have two parameters per input variable: a coefficient and an intercept. As long as our training data is representative enough, this typically prevents us from overfitting.
- Training and inference is pretty fast. This is largely a consequence of not having a lot of knobs to mess with. You can easily run a logistic regression on a laptop and have it train in seconds.
Applications in FRC
How does logistic regression help us? There’s lots of applications in the real world; Wikipedia has a pretty comprehensive list. Here’s just a few to whet your appetite:
- Predicting the species of an iris.
- Predicting the likelihood someone will vote for a particular political candidate.
- Predicting if a customer will purchase a product.
- Modeling the reliability of a service.
Given the broad applicability in the real world, it’s no surprise that logistic regression has tons of applications in FRC. You could use them to predict who will win matches, which teams will make the district championship, and predict how likely a team is to receive a particular robot award. And that’s just the beginning.
The trick with these tasks isn’t necessarily setting up a logistic regression; that’s the easy part. The hard part is figuring out what features to use, which requires a combination of intuition and a lot of fiddling.
Moving forward
Hopefully that was helpful in establishing a bit of background. In future blog posts in this series, we’ll work towards building a model that predicts if teams will win awards over a given year. Stay tuned for more!

[…] leveraging The Blue Alliance’s expansive data (you know how we love data), we’ve created the data-rich features like match breakdowns, event stats, and detailed […]