Happy holidays everyone! Here’s a present that might help tide you over until kickoff. 🙂 I’m beginning a 3-part series on analyzing ZEBRA Dart data. This is the first entry of the series, focusing on a general overview of the system and motion profiles.
Background
Last year, we started to see an uptick in the number of events that used ZEBRA Dart systems. These systems essentially provide real-time position estimates for every robot on the field in every match. The uses for this kind of data are virtually endless. I’ve been thinking for a long time about what would be the most sensical way to break down this data to make it as useful as possible. I’ve decided that I want a standalone tool that is easy to pick up and quickly customizable between years. As such, I’ve created a workbook called the ZEBRA Data Parser, which you can find on GitHub here.
I am planning to release three additional updates to this tool before the first 2020 event, two based on 2019 data (along with blog posts describing the updates), and one to pave the way for 2020. In the 2020 season, I am planning to pull data directly from this book into my scouting database for all in-season events that are equipped with Dart systems. This blog post will describe the basic capabilities of the data parser, and will help to lay the groundwork for more advanced analysis in future updates of it. Everything here is a work in progress, so if you have any bug reports or feature requests feel free to reach out to me. With that, let’s start with an overview of what data is provided to us by the Zebra system.
ZEBRA Dart Data Overview
The ZEBRA Dart Data currently is provided to us via csv files in a shared google drive folder. For example, here is the shared drive for the Chezy Champs 2019 data. I will be referring exclusively to this data for the remainder of this blog series. In this folder, there are team folders which contain all of the data from a given team’s matches. There is also a “Match” folder which contains data for all matches. Each csv file in the “Match” folder contains the ZEBRA data for all 6 teams participating in that match. For my analysis, I will be using the data from this “Match” folder as there are fewer files to parse through.
Each team’s match data consists of 3 separate data types, x-coordinates, y-coordinates, and times. The x-coordinate is the robot’s position in feet parallel to the long dimension of the field, with 0 being the red alliance wall and 54 being the blue alliance wall. The y-coordinate is the robot’s position in feet parallel to the short dimension of the field, with 0 being the wall nearest to the scoring table and 27 being the wall nearest to the audience. Time is the UTC time at which the data was collected. Since 10 data points are collected every second, and there are 150 seconds in a 2019 match, each team will produce approximately 1500 data points per match. As the ZEBRA Dart system is still very much in development for FRC, the data quality is not 100% accurate. There are two main data quality notes I’d like to address before going further.
The first data quality item is position uncertainty. x and y coordinates are reported to 2 decimal places, but the actual measurement noise is much higher than this. When I took a look at a team that was simply sitting in place for a few seconds, their position measurement would vary within a radius of approximately 0.08 ft (or about 1 inch). This is pretty good! You have to be careful though when looking at higher derivatives though. Since speed measurements divide position by 0.1 seconds, the speed measured by a resting robot can be up to 0.8 ft/s in any direction. Likewise acceleration measurements for a sitting robot can be up to 8ft/s^2, and jerk measurements can be up to 80 ft/s^3. To note this, I will be marking these noise thresholds on all graphs in this post. Due to this high noise using raw data, it may be beneficial to use a moving average for position measurements to smooth out these jumps. I did not do this for my analysis, but will potentially explore this option in the future.
The other prevalent data quality issue is that of missing data points, particularly at the start or end of the match. There are ways to compensate for missing data points that I will likely explore in the future, but for now I have opted instead to just throw out any team’s match data if they are missing data points. I’ll re-evaluate this choice as new data comes in for 2020. Another difficulty with the current system is that there is no way to know precisely when the match begins, I ended up choosing a time that is 1.6 seconds after the first team begins collecting data. Going earlier than this puts teams more out of sync with their apparent motions in videos, and going later causes more data quality issues due to missing data points at the end of the match. Out of the 101 matches at Chezy Champs, there are 606 possible team data sets. Of these, 280, or 46%, have no missing data points with my 1.6 second offset. Those will be the data-sets that I analyze for the rest of this blog series. Here is a link to a google sheet that contains all of the data used in this blog post.
Speed
We now have this huge amount of data, so what can we do with it? Well, the first thing we might want to look at is how each team moves around the field. The easiest thing to look at is each team’s speed. Matt Boehm actually already did this for SBPLI1, SBPLI2, and IRI in this thread. Measuring speed is pretty easy with position data. First, find each team’s change in x-coordinate and change in y-coordinate between consecutive data points. Then, use the good old pythagorean theorem on these changes to get the total distance moved. Speed is just distance moved over time, so take the total distance moved and divide by 0.1 seconds to get the instantaneous speed estimate. As mentioned above, speeds below 0.8 ft/s are expected just from measurement uncertainty, even if a robot is sitting still. To mark this, I’ve included a “noise threshold” at this speed, which approximately represents the slowest speed at which you can be confident a robot is actually moving. Here is a graph of all CC team speed percentiles from 0 to 95:
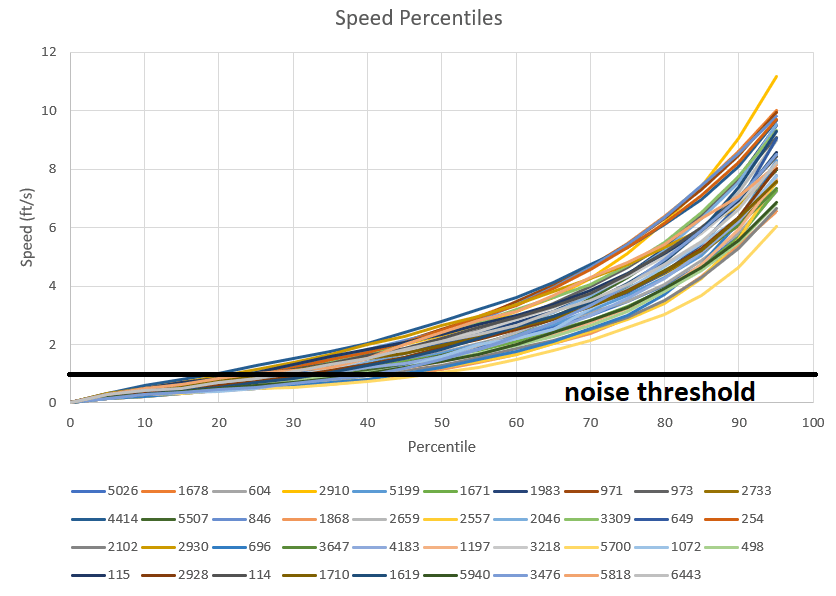
Since the above chart is a bit difficult to see with so many teams, I’ve selected 13 teams to show in the below chart:
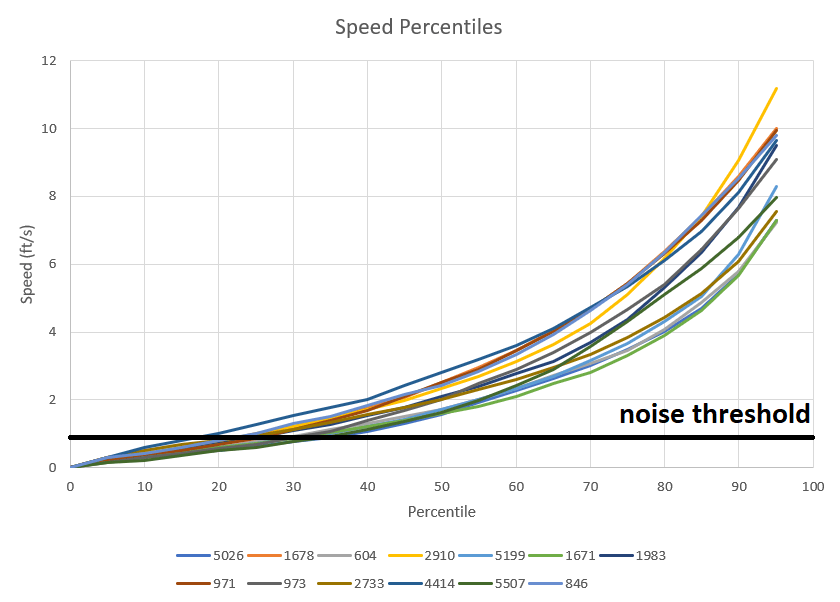
The percentile represents the percentage of time a robot moves at or below some speed. For example, 4414 has a 50th percentile speed of about 3 ft/s, which means that they spend about half of their time moving slower than 3 ft/s, and half of their time moving faster than 3 ft/s. I chose to neglect the 100th percentile since it only represents a single data point, which can be very noisy. Of these teams, 2910 had the highest top end speed (85+ percentile) but 4414 moved faster at the 70th percentile and lower. All teams seem to spend around 15% to 35% of their time under the noise threshold, meaning they are not moving or only moving slightly. For all teams, the average speed was 2.78 ft/s. 4414 had the highest average speed at 3.66 ft/s, and 5700 had the lowest average speed at 1.83 ft/s. Note that average speed is distinct from the 50th percentile, or median, speed. Average speed is the sum of all speeds divided by the number of measurement points, while median speed is the speed where 50% of speed measurements are lower and 50% are higher.
Acceleration
Measuring acceleration is done in a very similar way to measuring speed. Just find each team’s change in x-velocity and change in y-velocity, and use the pythagorean theorem again to find the total velocity change. Take this quantity and divide by 0.1 seconds again to get the total instantaneous acceleration. As with speed, I have selected 13 teams to show their acceleration percentile graphs, and have removed the 100th percentile due to noise. The noise threshold for acceleration is 8 ft/s^2. Here is that graph:
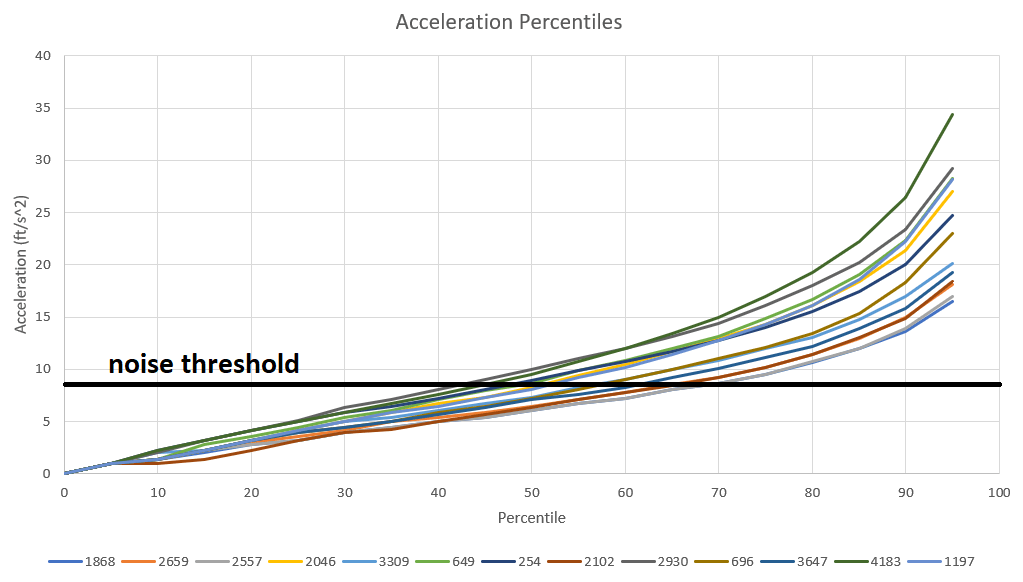
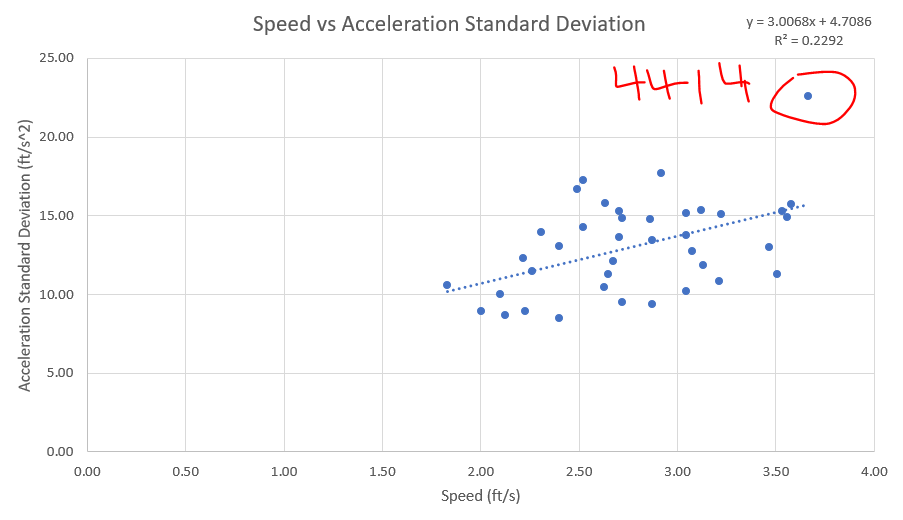
For reference, 32 ft/s^2 is the acceleration due to gravity at earth’s surface. Teams spend between 40% and 70% of their time below the noise threshold, meaning they are either not moving or moving at a relatively constant speed. Of these teams, 4183 has the highest acceleration for most of the range, while 2557 and 1868 have the lowest. For speed profiles, a high average is generally preferable, but for acceleration profiles, I’m not so sure. I lean toward the view that average acceleration is of little consequence. Rather, that the best acceleration profile stays near 0 at low percentiles, and then sharply increases at higher percentiles. To me, this kind of profile would indicate that a team is either positioning delicately for loading/scoring, or maxing out their motors to gain or lose speed as they are traveling the field. For a single number to represent this kind of acceleration profile, I think that the standard deviation of total acceleration works well. The standard deviation of acceleration will hopefully be an effective proxy for “efficient” driving in this sense. For all CC teams, the average acceleration standard deviation is 13.1 ft/s^2. 4414 has by far the highest acceleration standard deviation with 22.6 ft/s^2. Although 4414 tops both the average speed and the acceleration stdev lists, there is only a moderate correlation (0.48) between them, as shown by the below graph:
Acceleration Components
Velocity and acceleration are both vectors, and since vectors have both direction and magnitude, we can dig a little deeper into their data if we want. The above graphs only show the magnitudes of velocity and acceleration. Either vector on it’s own has little meaning to us, but we can compare the vector directions to see in which direction a team is accelerating relative to their direction of motion. This will give us two different acceleration components, one that is parallel to the direction of motion and one which is perpendicular. First, the parallel component. This can be found using the vector dot product. Applying this function between the acceleration vector and a normalized velocity vector gives us the component of acceleration parallel to motion. Positive values of the dot product indicate that the vectors are facing a direction that is within 90 degrees of each other, and negative values indicate that one vector is facing within 90 degrees of the other’s opposing direction. Since we are breaking into 2 components, the parallel acceleration noise threshold should approximately by 1/sqrt(2) or 70% of the total acceleration noise threshold, or around 5.5 ft/s^2. Here are the parallel acceleration profiles for the same 13 teams as were in the previous section:
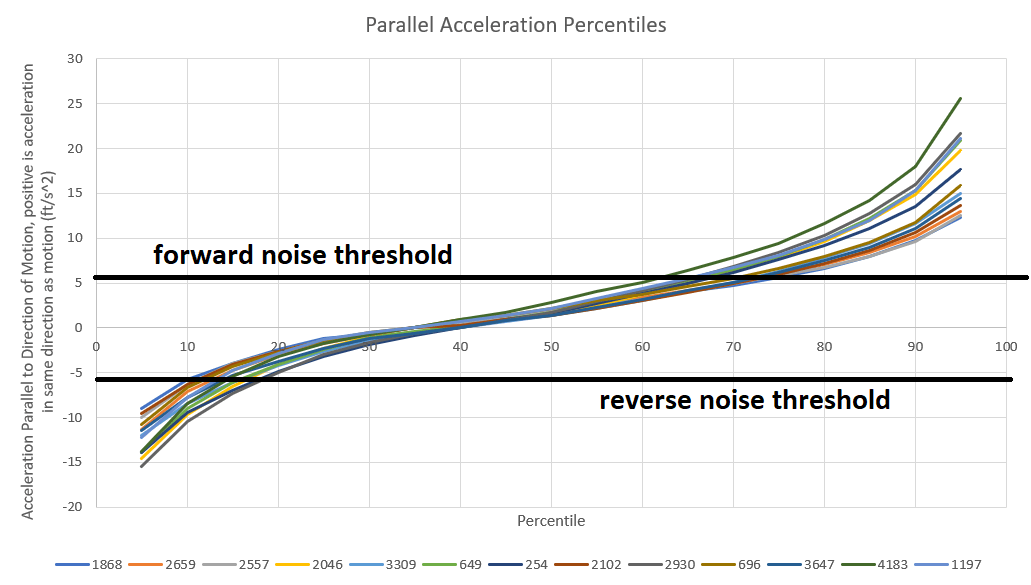
It is really interesting to me that, for each team, 60% to 65% of their acceleration time is in the same direction as their motion, while only 35% to 40% is in the reverse direction. What this indicates to me is that teams spend more time accelerating than decelerating. Likely because stopping tends to be done much more quickly than starting, from some combination of running into field elements, running into opposing robots, having speed controllers set to brake mode, and pulling back hard on the joysticks to brake. Other than that, the team order is almost equivalent to the raw acceleration graph in the above section.
Next, we have the perpendicular component of acceleration. This indicates how much acceleration is being used to change direction. To find this component, we can take the square of the total acceleration and subtract out the square of the parallel component. Taking the square root of this difference gives us the perpendicular component. This is just the pythagorean theorem again in disguise. We could assign left or right positive or negative values like we did for forward/reverse, but this has little meaning, so I just took the absolute value. Below are the perpendicular acceleration profiles for the same 13 teams:
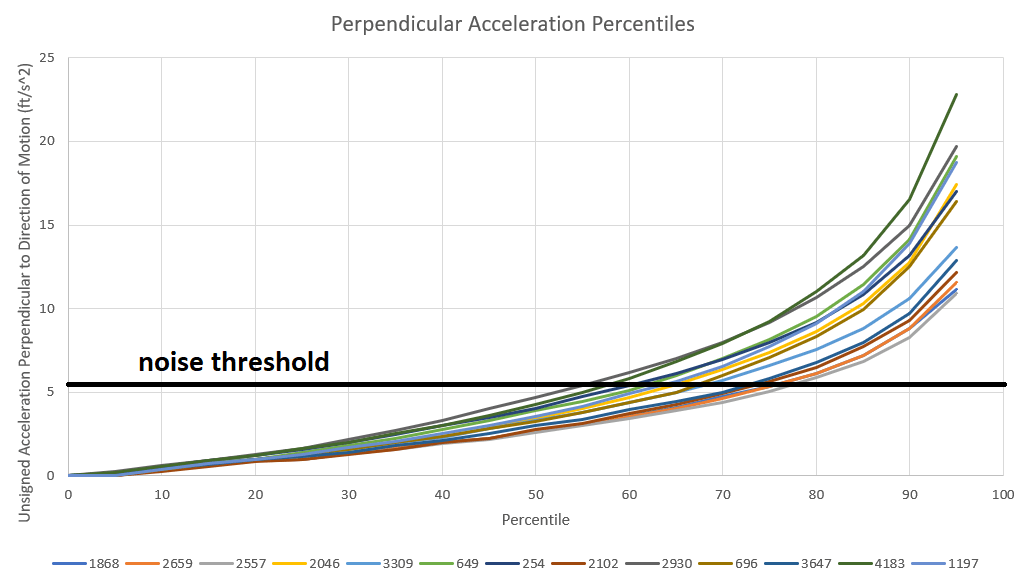
Again, this looks incredibly similar to the full acceleration graph, so I don’t think it adds much value. I had originally decided to calculate parallel and perpendicular acceleration profiles based on the hope that they would allow us to easily distinguish omni-directional driven teams from tank drive teams. I had thought that the perpendicular acceleration profiles for the omni-directional driven teams would be much higher than the tank drives, but that theory does not seem to hold up. I still hope that there will be some way to distinguish these drives based on their motion data, but alternative methods will have to be explored in the future to accomplish this.
Jerk
Here’s a quick physics and calculus lesson. Velocity is change in position divided by time (or, in calculus terminology, the time-derivative of position). Acceleration is change in velocity divided by time, or the second time-derivative of position. Finally, jerk is the change in acceleration divided by time, or the third time-derivative of position. Jerk is a quantity that measures how “jerky” or “rough” a body’s movement is, high jerk is often called whiplash, and low jerk is often considered “smooth”. Using the same methodology as for acceleration and speed, we find jerk by finding the x and y changes in acceleration, using the pythagorean theorem to get the total change in acceleration, and dividing by 0.1 seconds to get jerk. The noise threshold for jerk is around 80 ft/s^3. Here are the jerk profiles for the remaining 13 teams at Chezy Champs:
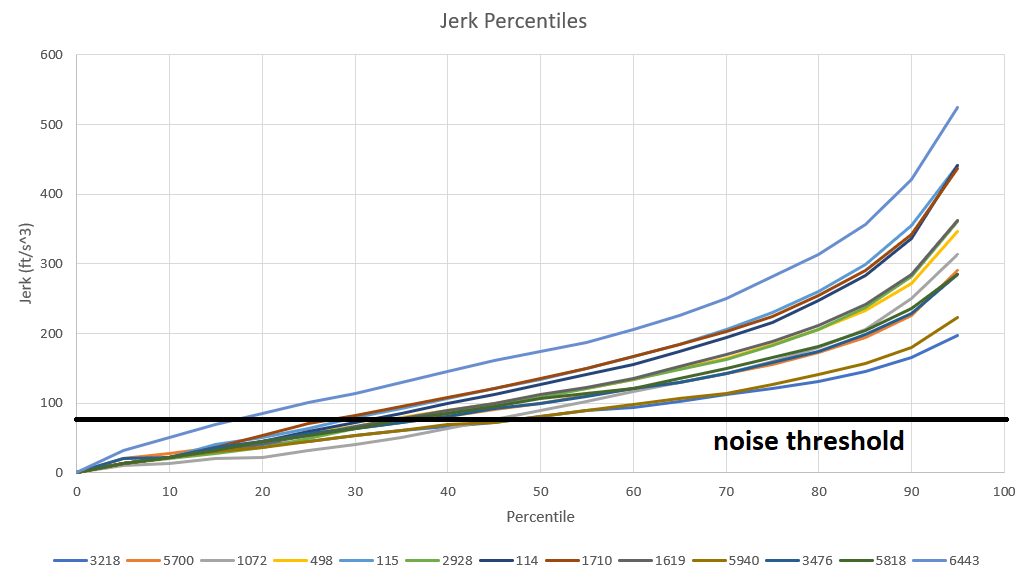
Among this group, 6443 has the highest jerk, with an average of 211 ft/s^3. 4414 has the highest average jerk of all teams at 241 ft/s^3. For all teams, the average jerk was 138 ft/s^3. For reference, according to this paper, jerks of 20 ft/s^3 are unacceptable for elevator passengers. It should also be noted that, as you go into higher and higher derivatives, small errors in position can multiply into much larger errors. My intuition tells me that this is a large part of why the jerks are so high.
Lower jerks would tend to indicate a “smoother” driving style all else held equal. Among all teams, 5026 had the lowest average jerk at 86 ft/s^3. This doesn’t tell the whole story though, because although 5026 had low jerk, they also had very low speed and acceleration compared to the field. Indeed, you could achieve near to zero jerk by simply sitting still the whole time. So be wary of looking at jerk alone.
Summary and Future Work
The ZEBRA Dart system provides a plethora of useful data. Data integrity is not perfect, particularly at the beginning and the end of matches, this will improve with better match start timestamps. Speed, acceleration, and jerk are some simple ways to extract information from position data. Generally, I believe that ideal motion profiles will have high speed, high standard deviation of acceleration, and low jerk. Breaking acceleration into components doesn’t seem to differentiate teams more than total acceleration does. All teams tend to decelerate more quickly than they accelerate.
This is just the first step in analyzing ZEBRA Data. The next is to break the field down into small zones that can be used to classify what robots are doing. Check out for that in part 2.
Until next time,
Caleb

[…] This is the second blog post in a series on ZEBRA Dart Analysis. You can check out the first post here. This post will talk about splitting the field into useful “zones” and then grouping […]
[…] of a three part blog series on analyzing ZEBRA MotionWorks (formerly Dart) data. Here are links to part 1 and part 2. This final post will focus on advanced insights we can get from applications of Zone […]